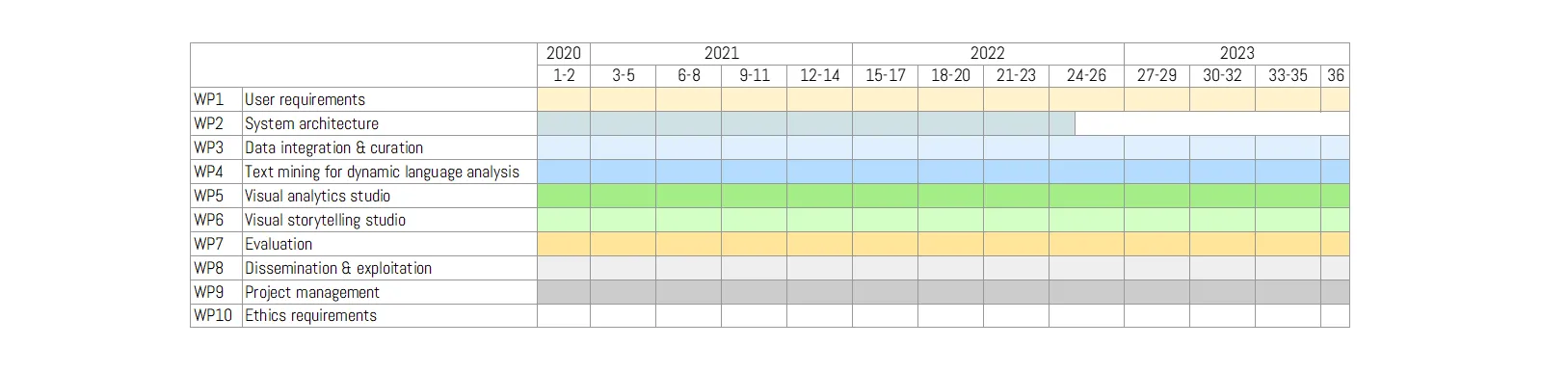
Work Packages
The InTaVia project is structured into ten work packages. These packages guide research and developments along parallel tracks, while being synchronized by project management and interwoven by deliverables, development dependencies, and consortial coordination.
WP01 - user requirements
To create expedient and valuable technologies for various user groups, the InTaVia platform will follow a user-centered design approach. For this purpose, WP1 will engage intended users (including cultural heritage practitioners and scholars, teachers, journalists, cultural heritage organizers and promoters) to collect their tasks, needs and aims (bundled as “exemplary user practices”) and define the system requirements on this basis together with all consortial working groups. After this initial phase, WP1 will consolidate these user practices, and develop practical guidelines (“operation designs”) to support such practices with the future system.
WP02 - information & system architecture
This work package is dedicated to the development of an integrated system architecture to connect the data from object database institutions with data and tools from the four national biographical database partners in the project. It will implement a central data hub, establish an exchange protocol, implement an API for interaction between the data hub and different tools and portals.
WP03 - data integration & curation
InTaVia brings together twelve data providers on the biography database side with their respective data models, and seven data providers for cultural object data. WP3 will develop an integrated, 'object-oriented' biography data model, and draw together resources into one coherent dataset serving as harmonized basis for visual analysis (WP5) and visual storytelling activities (WP6). This integration will be divided into three dimensions: harmonization of the schemas and data models, harmonization of the descriptive vocabularies, and linking/mapping of identical entities on the instance level. For evaluation and iterative improvement of the system a tool for the manual curation of structured data will be developed.
WP04 - text mining for dynamic language analysis
To enhance access to intangible sources—both for studying these sources themselves and for extracting information to shape stories around tangible sources—WP4 develops text mining technologies for analyzing historiographical texts in an interactive environment. One branch of the technologies focuses on extracting information and representing the information as structured data in RDF. We provide language-specific NLP models for German, Dutch, Finnish and Slovene for various text mining tasks (e.g. identify entities, places, dates, and events mentioned in the text). The other branch of technologies provides support for domain adaptation, identifying changes in language use (spelling, sense, or vocabulary) together with methods to verify stability and robustness of the neural networks used in the process.
WP05 - visual analytics studio
To make the integrated object-biography-database easier accessible/comprehensible, WP5 develops a visual analytics interface for the analysis and exploration of the data. It will implement a framework of coordinated views, provide multiple visual perspectives on data selections, and develop a visual query language for the compilation of data from very specific to very large selections. Further components will focus on the representation of data quality and provenance and on visually supported data creation and curation.
WP06 - visual storytelling suite
To support the communication and promotion of contextualized cultural heritage data to different audiences, we will develop a variety of narrative visualization and engagement techniques, which will enable the author-driven mediation and presentation of selected datasets while preserving the direct link to the related data-sources and therewith making the scientific basis of the storytelling transparent. A 'storytelling suite' will bundle the most effective narrative visualization templates to provide cultural heritage practitioners, teachers, journalists, organizers and promoters with the means to visually curate and communicate their selected cultural heritage topics. Connected to the expert-oriented visual analytics studio (WP5), this component will ensure the accessibility of complex cultural heritage contents for non-expert audiences and maximize aesthetic and hedonic qualities.
WP07 - evaluation
To ensure the system's usability and compliance to the needs of its target users, all InTaVia components will be evaluated. According to our overall approach of user-centered design, development and evaluation phases will be iterated to ensure the analytical efficiency, quality and expected impact of the data model (WP3), text mining (WP4), the visual analytics studio (WP6) and the visual storytelling suite (WP7) components – including their interplay on the system level.
WP08 - dissemination & exploitation
InTaVia will follow a strategic multi-level approach to project communication, dissemination and exploitation. WP8 will orchestrate and plan all related activities to effectively steer its data management and exploitation, intended to raise the awareness of all targeted audiences. By installing a project website, connecting to other digital humanities networks, and organizing events, workshops, and a conference, it aims to maximize the target communities' awareness of the project's results and the expected impact.
WP09 - project management
WP9 will carry out a comprehensive series of project and consortium management activities in order to link all project components and to manage and optimize the project's progress and resources. This includes the safeguarding of contractual requirements and consortial communication, as well as coordination with and reporting to the Commission.
WP10 - ethics requirements
WP10 will ensure compliance with the defined ethics requirements.